The first time I poked around inside Ghost's content/data folder I found a ghost.db file with zero bytes in it. That's the trap. Ghost used to ship with SQLite, then moved to MySQL, and the empty stub stayed behind — easy to assume it's the live database when in fact all the post content lives in MySQL with credentials buried in config.production.json. The 0-byte file is a fossil.
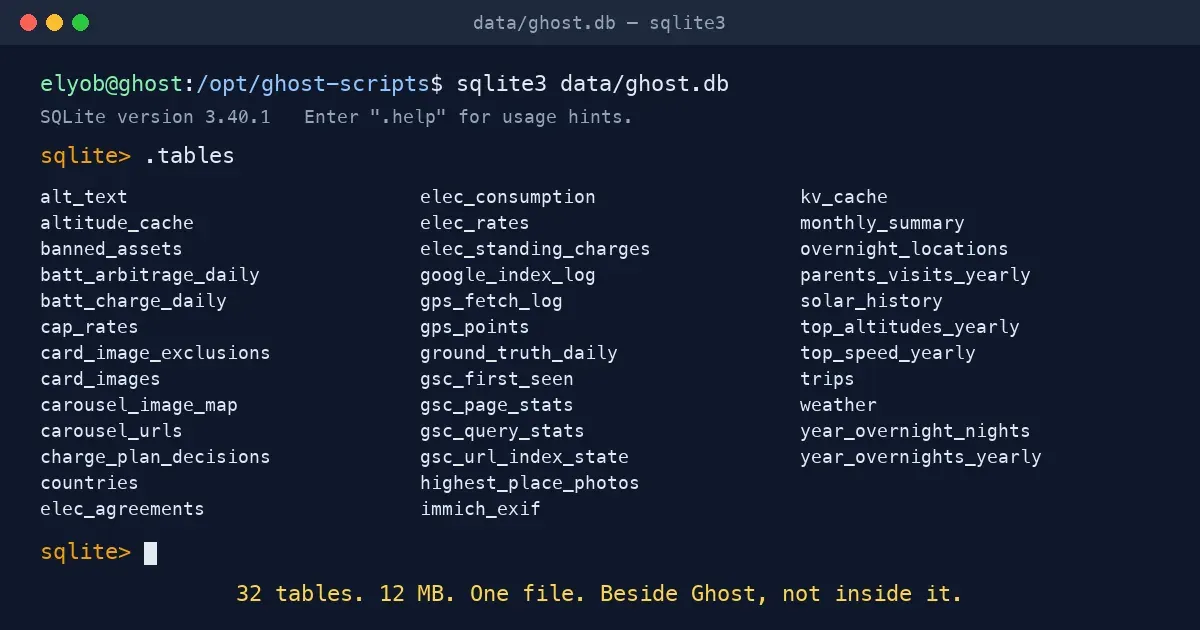
My own SQLite database — the one in this repo at data/ghost.db — is something else entirely. It runs beside Ghost, not inside it. Ghost handles posts, tags, members, themes; SQLite handles every piece of derived state I need around those posts: GPS summaries, solar telemetry, search-console history, the cache that stops me re-asking Claude for the same alt text twice. Two databases, two jobs, no overlap.
The 13 MB file at /opt/ghost-scripts/data/ghost.db is the entire reporting and automation layer behind everything custom on this site.
What's Actually In There
Right now it holds 44 tables. They group into six buckets, each with a clear job:
GPS & travel. gps_points caches Dawarich data so trip generators don't hammer the GPS server every run. overnight_locations records where I slept on each trip night (closest reading to 4 AM local time, timezone-aware). trips indexes them. gps_fetch_log audits which date ranges have already been pulled — without it, "is the GPS cache complete?" has no answer. The yearly rollups (top_altitudes, top_speed, year_overnight_nights, parents_visits) feed the per-year recap pages.
Energy raw + settled. elec_consumption holds every half-hour Octopus reading (~14,000 rows and growing). elec_rates, elec_standing_charges, and cap_rates track Agile and the price cap over time. solar_history records daily kWh per Home Assistant entity. batt_charge_daily and batt_arbitrage_daily are settled-day rollups. charge_plan_decisions logs every cron tick of the Agile charge planner — what mode it picked, which slots were cheap, what target SOC it set. ground_truth_daily and monthly_summary roll the half-hour numbers into reportable units.
Monitoring & intelligence. This is the layer that grew most this past month. drift_metrics z-scores round-trip efficiency, idle self-discharge, and wire temperatures against rolling 30-day baselines. forecast_accuracy tracks Solcast predictions vs what actually landed on the array. battery_health logs SOH and capacity drift over time. decision_economics computes per-cycle cap-vs-Agile-vs-actual costs. lp_shadow_compare and shadow_decisions store outputs from a Linear-Programming optimiser running alongside the live greedy planner — proving in shadow whether the LP would have done better, before swapping the live decision logic. alerts_log dedupes operational push notifications for the half-dozen things worth paging me on.
SEO. gsc_page_stats and gsc_query_stats mirror Google Search Console day-by-day. gsc_url_index_state and gsc_first_seen track when each URL first showed up in Google's index. The indexing tracker post reads from these tables every time it regenerates.
Ghost helpers. alt_text caches photo descriptions keyed by perceptual hash, so the same photo never costs me a second Claude Haiku call. card_images powers the JS that swaps trip-page hero maps for photo thumbnails on the homepage. carousel_image_map and carousel_urls handle multi-image post layouts. banned_assets is the do-not-show list. immich_exif caches camera metadata to avoid round-tripping the photo server.
Caches. kv_cache is the single shared key-value store for the canonical savings helper and other expensive-to-recompute lookups. altitude_cache memoises elevation-API calls for trip-mapping.
Three Loops, One Database
The biggest payoff isn't any single feature — it's that the same SQLite file feeds three loops with different rhythms.
The fast loop is the planner. Every 30 minutes the agile_charge_planner cron writes a row to charge_plan_decisions and reads from drift_metrics and ground_truth_daily to decide how many hours of cheap-slot grid charging to book. That's milliseconds of SQL hidden behind a tick of cron.
The slow loop is the daily batch. At 16:30+ UTC each day a chain of crons computes forecast_accuracy, drift_metrics, battery_health, decision_economics, and the LP-shadow comparison. Yesterday's data has finally settled by then; today's is ready to be summarised tomorrow.
The reporting loop is the page generator. solar.py, update_roi_post.py, and the indexing tracker query the same tables and render charts directly into Ghost posts. The /solar dashboard reads charge_plan_decisions for the live decision card; the ROI post pulls ground_truth_daily and decision_economics for the cap-vs-Agile chart; the Google indexing post is fed entirely from the gsc_* tables.
None of those page generators query Home Assistant or Octopus directly — they all go through the SQLite intermediary. The dashboard refreshes in milliseconds even if HA is offline, the ROI post never makes external calls during render, and any upstream system can drop out without taking the customer-facing pages down with it.
The Settled-Day Pattern
Most of the energy tables follow the same shape: only cache yesterday and earlier, never trust today. Half-hour readings can arrive late, get amended, or just be wrong for the first few hours. The cron jobs that build ground_truth_daily and friends only ever write rows for days that won't change again. Today is always recomputed from source.
That keeps the cache cheap to invalidate (delete a row) and means there's no partial-day state to reconcile. The same idea shows up in gps_fetch_log — a tiny audit table that records which date ranges have already been pulled from Dawarich. Without it, "is the GPS cache complete?" has no answer; with it, the trip generators skip ranges already imported and a force=True flag invalidates a window when a fresh pull is needed.
Source of Truth, Derived State
The rule I learned the hard way: raw data belongs at its authoritative source, not in SQLite. Dawarich is the GPS server; it owns the raw track. Immich owns the photos and their EXIF. Octopus owns the half-hour reads. Home Assistant owns the realtime sensor stream. Ghost owns the posts.
My SQLite holds derived state — summaries, joins between systems, caches that exist only to make rebuilds fast. If ghost.db were deleted tomorrow I could rebuild every row from upstream sources in a few hours of cron runs. That's the test: anything in the file should be reconstructible from elsewhere. Anything that isn't doesn't belong here.
That distinction matters because raw data wants to live in a system that knows how to handle it. Mirroring every GPS point into ghost.db sounds tidy until "where was I on 14 March 2024 at 3 PM" needs answering — Dawarich already does that better, with a UI, with backups, and with the right indexes. The gps_points table I do keep is a thin cache: trip-window points only, used solely for map generation.
What the Monitoring Layer Buys Me
Adding the monitoring tables turned an event-driven system into a learning one. The drift detector catches things I'd never spot manually: round-trip efficiency creeping down, idle self-discharge climbing, the wire-temp baseline shifting. Each metric is z-scored against its own 30-day rolling history, so seasonal effects don't trigger false alarms.
The LP shadow runs a full 48-hour Linear-Programming optimisation alongside the live greedy planner every cycle. lp_shadow_compare records what each would have decided. Over enough cycles I'll know whether the LP genuinely beats the cost-aware greedy or just performs the same — useful evidence before swapping the production decision logic.
alerts_log exists so push notifications don't spam me. Each alert has a fingerprint (e.g. wire_temp:abs_panic); within a 6-hour window the same fingerprint is suppressed. That lets the cron fire every 10 minutes without becoming noise. The wire-temp panic alert is the only one wired to also auto-stop the charger via timer.finish — every other alert is notify-only, the operator decides.
The Takeaway
The temptation in a setup like this is to lean on Home Assistant for everything. I'd resist that. HA is excellent at the realtime control plane — read a sensor, write a switch, fire an automation — but it is not where reporting data should live, and it's definitely not where multi-source analytics should be computed.
SQLite, sitting beside HA and pulling from it, is the right place for "what happened last Tuesday" questions, "did the planner under-predict drain again this month" questions, and "is the wire temp creeping" questions. The HA-Python-SQLite split keeps each system doing what it's best at: HA controls, SQLite remembers, Python reasons across both.
The 0-byte fossil at content/data/ghost.db will stay there forever, I assume — Ghost has no reason to remove it. Mine, the one that actually does the work, lives one directory over and one mental model away. It started as a small cache for trip generators; it's grown into the reporting and automation backbone for everything from charge planning to wire-temperature alerting. 13 MB, 44 tables, and the entire intelligence layer of this site.